Squid Caching
Zur Navigation springen
Zur Suche springen
Caching
- Squid kann auch Seiten zwischenspeichern.
- Durch das Aufkommen von dynamischen Webseiten wird dieser Aspekt aber immer unwichtiger

Sinnvolles Caching
- Ein viel größeres Problem ist es, daß die Lebensdauer von Web-Seiten sehr unterschiedlich ist.
- Dadurch kann nie mit Sicherheit bestimmt werden, wann sich eine Seite ändert und dadurch veraltet ist und aus dem Cache gelöscht, bzw. beim Server neu angefordert werden soll.
- Es kann also immer vorkommen, daß der Cache ein veraltetes Dokument an den Client liefert.
- Durch verschiedene Strategien wird versucht, dieses Manko so weit wie möglich auszugleichen.
- HTTP bietet dazu zwei Möglichkeiten: Last-Modified und Expires.
- Mit der Antwort des Servers werden diese Information an den Proxy mitgeteilt.
- Mit Last-Modified wird angezeigt, wann das Dokument das letzte mal geändert wurde.
- Mit der Angabe Expires erhält der Client (in diesem Falle der Proxy) Informationen, wann er das Dokument als veraltet ansehen soll und vom Server neu anfordern muß.
- In einem HTML-Dokument werden diese Angaben im Header generiert.
- Dazu wird das META-Element benutzt.
- Die Informationen sehen dann wie im folgenden Beispiel aus:
<META HTTP-EQUIV=“Last-Modified“ CONTENT=“Thu Jan 1 12:00:00 GMT DST 1998“>
<META HTTP-EQUIV=“Expires“ CONTENT=“Thu Dec 31 12:00:00 GMT DST 1998“>
- Allein die Expires-Angabe würde reichen, um den Cache in dieser Hinsicht zu optimieren.
- Jedoch sind diese Angaben optional und werden sehr selten eingesetzt.
- Außerdem ist es oft schwierig die Lebensdauer einer Web-Seite vorauszusagen.
- Daher sind die meisten Web-Seiten einfach so lange gültig, bis der Autor eine neue Version erstellt.
- Anders sieht es bei Last-Modified aus.
- Diese Angabe findet sich zwar selten explizit in HTML-Dokumenten, jedoch trägt jedes Dokument als Datei einen Zeitstempel,
- Dieser wird vomServer dann als Last-Modified-Header mitgeliefert.
- Die Proxy-Server wenden damit ein einfaches Verfahren ein, um die Lebensdauer eines Dokumentes zu „erraten“.
- Dabei wird zugrunde gelegt, daß die Wahrscheinlichkeit recht gering ist, daß ein recht altes Dokument in den nächsten Stunden geändert wird.
- Bei einem Dokument, welches dagegen erst vor kurzem geändert wurde, ist die Möglichkeit einer baldigen Aktualisierung eher vorhanden.
- Sofern ein Objekt keinen Expires-Header aufweist, erzeugt der Proxy-Server mit Hilfe des Last-Modified-Headers ein künstliches Verfallsdatum.
- Dazu bestimmt er das Alter der Datei und schlägt einen Prozentsatz dazu, der bei der Konfiguration des Proxy-Servers eingetragen wird *(Direktive refresh_pattern)
- Es holt frühestens nach Ablauf dieser Zeit von sich aus das Dokument erneut vom Server.
- Ist beispielsweise ein Dokument zum Zeitpunkt der ersten Anfrage des Proxies bereits 150 Tage alt
- Und der Prozentsatz aus der Konfiguration ist 20%,
- So vergehen weitere 30 Tage, bis der Proxy-Server eine erneute Anfrage an den Originalserver stellt.
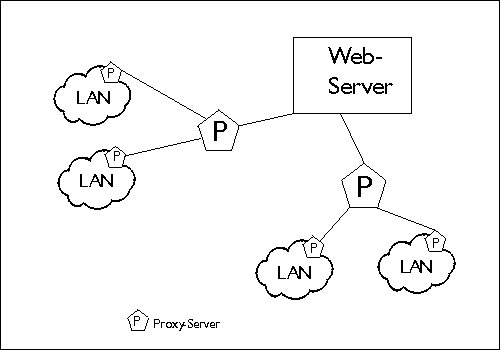
Hierarchisches Caching
- Bei einigen Proxy-Servern ist es möglich, die Größe des Caches anzugeben, welcher im Hauptspeicher des Rechners liegt.
- Übertragene Objekte werden dort eine gewisse Zeit gehalten, um schnellere Antwortzeiten zu erreichen,
- Falls ein Objekt innerhalb kurzer Zeit von zwei verschiedenen Clients angefordert wird.
- Dabei kann meist über den Parameter TTL (Time-to-Live) die Zeitdauer angegeben werden, die ein Objekt maximal in diesem Cache gehalten wird.
- Eine weitere Möglichkeit, die Performance zu erhöhen und geringere Antwortzeiten zu erhalten, ist das hierarchische Caching.
- Banal gesagt setzt man einen Proxy für den Proxy ein.
- Dadurch kann die Trefferquote auf Objekte nochmals verbessert werden.
- Dies macht besonders deshalb Sinn, da die Datenmengen immer größer werden und es immer wieder zu Engpässen kommt.
- Das hierarchische Caching führt dabei zu einer Entlastung.
- Damit die Proxy-Caches miteinander kommunizieren können, wurde ein spezielles Protokoll entwickelt, das ICP (Internet Caching Protocol).
- Dabei schicken Proxy-Caches für das gewünschte Objekt Anfragen an benachbarte und in der Hierarchie höher stehende Proxy-Caches.
- Ist das Objekt in einem dieser Caches vorhanden, wird es übertragen, andernfalls wird es vom Originalserver geholt.
- Da das ICP auf UDP basiert, ist es sehr schnell und bedeutet somit einen vertretbaren Performanceverlust, der durch eine erhöhte Trefferquote mehr als ausgeglichen wird.

Begriffe
| Neighbours | Dies sind alle Proxies, die ein Proxy kennt und mit denen er kommuniziert. |
| Siblings | Die Geschwisterproxies. Sie liegen mit dem Proxy-Server auf einer Ebene. Siblings liefern in der Regel nur Objekte, die sie selbst im Cache haben, |
| Parents | Übergeordnete Proxies. Sie liefern Objekte die sie selbst im Cache haben und leiten Anfragen an den Originalserver weiter. |
Funktionsbeschreibung
- Squid, der Internet Object Cache, ist jedoch mehr als ein einfacher Cache-Proxy.
- Durch die Unterstützung von Neighbor-Caches, die entweder als parent oder sibling verwendet werden, kann man einen Cache-Verbund aufbauen, der einen hohen Prozentsatz von Anfragen beantworten kann, ohne langwierige Internet-Zugriffe zu erfordern.
- Dieses Verfahren verwenden zum Beispiel einige der großen Internet-Provider (wie ECRC in München), um den Datentransfer wenn möglich auf der eigenen Netzwerkstruktur abzuwickeln und damit Kosten für externe Zugriffe zu umgehen.
Die Arbeitsweise von Squid ist einfach
- Eine Anfrage eines Clients wird zuerst auf die Zugriffsberechtigung untersucht, so kann man z.B. gewissen Rechnern einen Zugriff auf den Proxy ganz verbieten (siehe Konfiguration).
- Es wird versucht, die gewünschten Daten im lokalen Cache zu finden. Sollte dies fehlschlagen, werden andere Proxies im Cache-Verbund (sofern vorhanden), abgefragt.
- Sind die Daten vorhanden, wird ihre Aktualität geprüft. Sind die Daten veraltet, werden neue in den Cache geholt und an den Client weitergegeben.
- Bei aktuellen Daten wird das Neuladen übersprungen.
- Sind die Daten nicht vorhanden, werden sie in den Cache geladen und an den Client weiter-gereicht.
- Wie lange Daten im Cache verbleiben, ist abhängig von der Konfiguration (siehe dort)
- Eine Beschreibung der internen Abläufe wurde im Sinne der Übersichtlichkeit weggelassen.